以框架目前的完成度来说,handler中还需要我们手动的构建http响应报文,不仅麻烦而且容易出错。因此我们今天就要完成对response的封装,提供更易操作的api以及完成对响应报文的自动构建。本文难度较高,是该系列的最后一个难点。
项目结构
今天的项目结构如下:
6
|-- go.mod
|-- httpd
| |-- chunk.go
| |-- conn.go
| |-- header.go
| |-- multipart.go
| |-- request.go
| |-- response.go
| |-- server.go
| |-- status.go
|-- main.go
|-- test.html
|-- test.webp
新增了status.go文件,对conn.go、chunk.go、response.go、request.go做出了修改。
test.html是测试网页,test.webp是测试图片。
代码传送门
报文分析
来看一段服务端响应给客户端的响应报文:
1
2
3
4
5
|
HTTP/1.1 200 OK\r\n #状态行
Content-Length: 20\r\n
Content-Type: text/html; charset=utf-8\r\n
\r\n
<h1>hello world</h1>
|
- 第1行为状态行,有三个部分,分别为协议版本,状态码以及状态码的描述。
- 第2~3行为响应首部,响应首部后跟随两个CRLF。
- 第5行为响应报文主体。
你会发现响应报文与请求报文极其相似。服务端也是通过Content-Length或者chunk编码的方式,来告知客户端将报文主体完整读出。
以我们目前的框架写法来构建这个报文,过于繁琐:
1
2
3
4
5
6
7
|
func (*myHandler) ServeHTTP(w httpd.ResponseWriter, r *httpd.Request) {
str:="<h1>hello world</h1>"
io.WriteString(w,"HTTP/1.1 200 OK\r\n") //状态行
io.WriteString(w,fmt.Sprintf("Content-Length: %d\r\n",len(str)))
io.WriteString(w,"Content-Type: text/html; charset=utf-8\r\n\r\n")
io.WriteString(w,str)
}
|
从构建一个完整的报文的角度出发,我们的框架其实只需要用户提供一个状态码以及相应欲发送的报文主体即可。对于状态行的其他部分如http协议版本以及状态码描述等信息,可以由框架填充。Content-Length也可以根据用户Write数据的多少自动设置,同理Content-Type也可以利用嗅探算法进行探测。
我们给ResponseWriter增添两个方法:WriteHeader以及Write,分别用于写状态码以及发送报文主体。
同时为了让用户更方便的设置报文首部,我们提供一个Header方法,来返回header这个map,因此ResponseWriter接口如下:
1
2
3
4
5
|
type ResponseWriter interface {
Write([]byte) (n int, err error)
Header() Header
WriteHeader(statusCode int)
}
|
这三个方法正好满足用户构建一个响应报文的所有需求。这就是标准库为什么这么设计ResponseWriter的原因。
实现思路
上面提到我们框架要将一些非必要的工作揽到自己的头上,让用户专注于自己的逻辑代码的实现,现在讲讲如何去实现这些自动化的工作。
难点是Content-Length的设置,其实这时我估计你心里早就有了解决方案,我们只需要将用户所有欲发送的数据先缓存起来,等handler结束后,我们就可以知道用户想要响应多长的报文主体,接着设置Content-Length,最后将缓存的数据发送给客户端。
问题是handler中用户可能Write很大的数据,我们将这些数据全部缓存是极为消耗资源的事情,因此我们要在必要的时候利用chunk编码的方式发送响应报文主体。
我们框架的解决方案是规定最多缓存4KB数据,如果用户在handler中写入的量小于这个值,我们使用Content-Length,否则使用chunk编码的方式。
那么为什么不直接全部采用chunk编码的方式呢,这样明明可以大大减少设计的复杂度。这是因为chunk编码的解析效率会比Content-Length方式低上很多,同时也有控制信息等数据开销,我们要兼顾性能进行考虑。
现在我们的目标就很明晰了,就是实现上面两种情况的智能转换。区分这两种情况的要义就是handler结束时累计写入到缓存的数据是否超过4KB,一定要紧抓这一点。
我们抽象出了一个chunkWriter的结构,给其分配一个4KB的缓存封装成一个bufio.Writer,在handler中用户给response的Write就是对这个bufio.Writer的Write,显然既然用到了bufio.Writer就要在handler结束后调用配套的Flush方法,将还缓存的数据Write到chunkWriter中。根据bufio.Writer的特性,我们只有两种时机会触发chunkWriter的Write方法:
- 在handler结束之前,用户在handler中对bufio.Writer写入的数据超过了4KB这个缓存大小。
- 在handler结束之后,调用了FLush方法。
第一种情况正好对应于使用chunk编码,第二种情况说明handler写入的数据未超过缓存大小,正好适用于使用Content-Length。
所以我们实现chunkWriter的Write方法时,只需要检测第一次触发这个Write时handler是否结束,就可以知道该用哪一种编码方式,后续只要构建相应的报文主体即可。
response
用户handler中的ResponseWriter接口其实就是这个response,我们要实现上述的三个方法。
- WriteHeader用于写入状态码,因此我们增加statusCode成员来保存。
- Header是用于设置相应头部,我们增加header成员这个map来保存。
- Write是用于写数据,上面提到handler对response的写是对bufio.Writer的写,我们增加一个bufw。
除此之外,添加了handlerDone属性用来标识handler是否结束,显然在handler结束后在(*Request).finishRequest方法中应该将其设为true。我们的chunkWriter通过这个handlerDone就可以决定采用哪种编码方式。
还添加了一个closeAfterReply字段,这是因为我们的框架是HTTP/1.1版本的,支持长连接,在某些情况(见注释)下不应该维持这个长连接,我们通过这个来标识是否要在当前请求结束后关闭长连接(对应于conn.go的serve方法中的for循环)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
type response struct {
//http连接
c *conn
//是否已经调用过WriteHeader,防止重复调用
wroteHeader bool
header Header
//WriteHeader传入的状态码,默认为200
statusCode int
//如果handler已经结束并且Write的长度未超过最大写缓存量,我们给头部自动设置Content-Length
//如果handler未结束且Write的长度超过了最大写缓存量,我们使用chunk编码传输数据
//会在finishRequest中,调用Flush之前将其设置成true
handlerDone bool
//bufw = bufio.NewBufioWriter(chunkWriter)
bufw *bufio.Writer
cw *chunkWriter
req *Request
//是否在本次http请求结束后关闭tcp连接,以下情况需要关闭连接:
//1、HTTP/1.1之前的版本协议
//2、请求报文头部设置了Connection: close
//3、在net.Conn进行Write的过程中发生错误
closeAfterReply bool
//是否使用chunk编码的方式,一旦检测到应该使用chunk编码,则会被chunkWriter设置成true
chunking bool
}
|
接下来就是chunkWriter的设置,chunkWriter这个结构要负责响应报文状态行、首部字段以及报文主体的构建。因此我们让其保存response的指针,可以随时访问response的成员。比如response的req、statusCode成员来构建状态行,header成员来构建响应首部,c成员的bufw来将数据发送到net.Conn上。注意c成员的bufw区别于response的bufw成员,前者是对net.Conn的封装(见本系列第一篇),后者是对chunkWriter的封装。
除此之外,chunkWriter还负责设置response的chunking成员,因为chunk编码最后是以0\r\n\r\n为结束标识,如果chunking为true的话我们需要在handler结束后的finishRequest方法中将这个结束标识发送出去。chunkWriter的结构体如下:
1
2
3
4
5
|
type chunkWriter struct {
resp *response
//记录是否是第一次调用Write方法
wrote bool
}
|
最后捋一下Write写入流的顺序:用户在handler中对ResponseWriter写 => 对response写 => 对response的bufw成员写 => bufw是chunkWriter的封装,对chunkWriter写 => 对(*chunkWriter).(*response).(*conn).bufw写 => 这个bufw是对net.Conn的封装,对net.Conn写。
每一个箭头都是一个Writer的封装,希望读者好好体悟这个过程。
接着给response的添加三个方法,都比较常规:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
//写入流的顺序:response => (*response).bufw => chunkWriter
// => (*chunkWriter).(*response).(*conn).bufw => net.Conn
func (w *response) Write(p []byte) (int, error) {
n,err:=w.bufw.Write(p)
if err!=nil{
w.closeAfterReply = true
}
return n,err
}
func (w *response) Header() Header{
return w.header
}
func (w *response) WriteHeader(statusCode int){
if w.wroteHeader{
return
}
w.statusCode = statusCode
w.wroteHeader = true
}
|
并相应更改setupReponse这个初始化函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
func setupResponse(c *conn,req *Request) *response {
resp:=&response{
c: c,
header: make(Header),
statusCode: 200,
req: req,
}
cw := &chunkWriter{resp: resp}
resp.cw = cw
resp.bufw = bufio.NewWriterSize(cw,4096)
var(
protoMinor int
protoMajor int
)
fmt.Sscanf(req.Proto,"HTTP/%d.%d",&protoMinor,&protoMajor)
if protoMajor<1 || protoMinor==1&&protoMajor==0 || req.Header.Get("Connection")=="close"{
resp.closeAfterReply = true
}
return resp
}
|
使用了bufio.Writer,我们就需要调用配套的Flush方法,将缓存区的数据发送到底层的chunkWriter上去,我们需要修改request.go的finishRequest方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
func (r *Request) finishRequest(resp *response) (err error) {
if r.multipartForm != nil {
r.multipartForm.RemoveAll()
}
//告诉chunkWriter handler已经结束
resp.handlerDone = true
//触发chunkWriter的Write方法,Write方法通过handlerDone来决定是用chunk还是Content-Length
if err = resp.bufw.Flush(); err != nil {
return
}
//如果是使用chunk编码,还需要将结束标识符传输
if resp.chunking{
_,err = resp.c.bufw.WriteString("0\r\n\r\n")
if err!=nil{
return
}
}
if err = r.conn.bufw.Flush(); err != nil {
return
}
_, err = io.Copy(ioutil.Discard, r.Body)
return err
}
|
接着我们需要在conn.go的serve方法中,判断是否需要提前终止tcp长连接:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
func (c *conn) serve() {
defer func() {
if err := recover(); err != nil {
log.Printf("panic recoverred,err:%v\n", err)
}
c.close()
}()
//http1.1支持keep-alive长连接,所以一个连接中可能读出
//多个请求,因此实用for循环读取
for {
req, err := c.readRequest()
if err != nil {
handleErr(err, c)
return
}
resp := c.setupResponse(req)
c.svr.Handler.ServeHTTP(resp, req)
if err = req.finishRequest(resp); err != nil {
return
}
//add
if resp.closeAfterReply{
return
}
}
}
|
目前为止response的工作就结束了。
chunkWriter
接下来就是重点探讨chunkWriter,它的职责就是构建响应报文包括状态行、响应首部以及报文主体,同时也负责决定是采用Content-Type还是chunk编码。
再叨唠一句,两种情况触发chunkWriter的Write方法:
- 在handler中对bufio.Writer(即response.bufw)的写超过4KB,这时handlerDone为false,应使用chunk编码。
- 在handler结束后,finishRequest中调用response.bufw.Flush方法,这时handlerDone为true,应使用Content-Type。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
|
type chunkWriter struct {
resp *response
wrote bool
}
func (cw *chunkWriter) Write(p []byte) (n int, err error) {
//第一次触发Write方法
if !cw.wrote {
cw.finalizeHeader(p)
if err = cw.writeHeader(); err != nil {
return
}
cw.wrote = true
}
bufw := cw.resp.c.bufw
//当Write数据超过缓存容量时,利用chunk编码传输,chunk编码格式见该系列(4)。
if cw.resp.chunking {
_,err = fmt.Fprintf(bufw,"%x\r\n",len(p))
if err!=nil{
return
}
}
n,err = bufw.Write(p)
if err == nil && cw.resp.chunking{
_,err=bufw.WriteString("\r\n")
}
return n,err
}
//设置响应头部
func (cw *chunkWriter) finalizeHeader(p []byte) {
header := cw.resp.header
//如果用户未指定Content-Type,我们使用嗅探。因为嗅探算法并非重点,我们这里直接使用标准库提供的api
if header.Get("Content-Type") == "" {
header.Set("Content-Type", http.DetectContentType(p))
}
//如果用户未指定任何编码方式
if header.Get("Content-Length") == "" && header.Get("Transfer-Encoding") == "" {
//因为Flush触发该Write
if cw.resp.handlerDone {
buffered := cw.resp.bufw.Buffered()
header.Set("Content-Length", strconv.Itoa(buffered))
} else {
//因为超出缓存触发该Write
cw.resp.chunking = true
header.Set("Transfer-Encoding", "chunked")
}
return
}
if header.Get("Transfer-Encoding") == "chunked"{
cw.resp.chunking = true
}
}
//将响应头部发送
func (cw *chunkWriter) writeHeader() (err error) {
codeString := strconv.Itoa(cw.resp.statusCode)
//statusText是个map,key为状态码,value为描述信息,见status.go,拷贝于标准库
statusLine := cw.resp.req.Proto + " " + codeString + " " + statusText[cw.resp.statusCode] + "\r\n"
bufw := cw.resp.c.bufw
_, err = bufw.WriteString(statusLine)
if err != nil {
return
}
for key, value := range cw.resp.header {
_, err = bufw.WriteString(key + ": " + value[0] + "\r\n")
if err != nil {
return
}
}
_, err = bufw.WriteString("\r\n")
return
}
|
重点就是判断第一次触发chunkWriter的Write时,handler是否为结束即可。我们会在第一次触发Write时,设置响应头部并发送。
有些细节还是要注意下,比如如果用户主动设置了Content-Type、Content-Length或者Transfer-Encoding: chunked话,我们应该还是以用户为准。
目前我们的框架还存在一个Bug,那就是如果用户提供的handler中未调用ResponseWriter的Write方法,就不会触发chunkWriter的Write以及writeHeader方法,框架也就不会将响应报文发送出去,所以我们需要在finishRequest中手动触发writeHeader:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
func (r *Request) finishRequest(resp *response) (err error) {
if r.multipartForm != nil {
r.multipartForm.RemoveAll()
}
resp.handlerDone = true
if err = resp.bufw.Flush(); err != nil {
return
}
//将最后的0\r\n\r\n传输
if resp.chunking {
_, err = resp.c.bufw.WriteString("0\r\n\r\n")
if err != nil {
return
}
}
//-------------------------------------------------------------------
//如果用户的handler中未Write任何数据,我们手动触发(*chunkWriter).writeHeader
if !resp.cw.wrote {
resp.header.Set("Content-Length", "0")
if err = resp.cw.writeHeader(); err != nil {
return
}
}
//-------------------------------------------------------------------
//将缓存中的剩余的数据发送到rwc中
if err = r.conn.bufw.Flush(); err != nil {
return
}
_, err = io.Copy(ioutil.Discard, r.Body)
return err
}
|
测试
main.go代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
package main
import (
"example/httpd"
"fmt"
"io"
"io/ioutil"
"os"
)
type myHandler struct{}
func (*myHandler) ServeHTTP(w httpd.ResponseWriter, r *httpd.Request) {
if r.URL.Path == "/photo"{
file,err:=os.Open("test.webp")
if err!=nil{
fmt.Println("open file error:",err)
return
}
io.Copy(w,file)
file.Close()
return
}
data,err:=ioutil.ReadFile("test.html")
if err!=nil{
fmt.Println("readFile test.html error: ",err)
return
}
w.Write(data)
}
func main() {
svr := &httpd.Server{
Addr: "127.0.0.1:80",
Handler: new(myHandler),
}
panic(svr.ListenAndServe())
}
|
test.html的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport"
content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<img src="/photo">
</body>
</html>
|
test.html的文件大小小于4KB,test.webp的文件大小大于4KB。
浏览器访问http://127.0.0.1,能够正常显示这张图片。浏览器中F12可以查看两个http请求的会话:
对/请求:

对/photo请求:
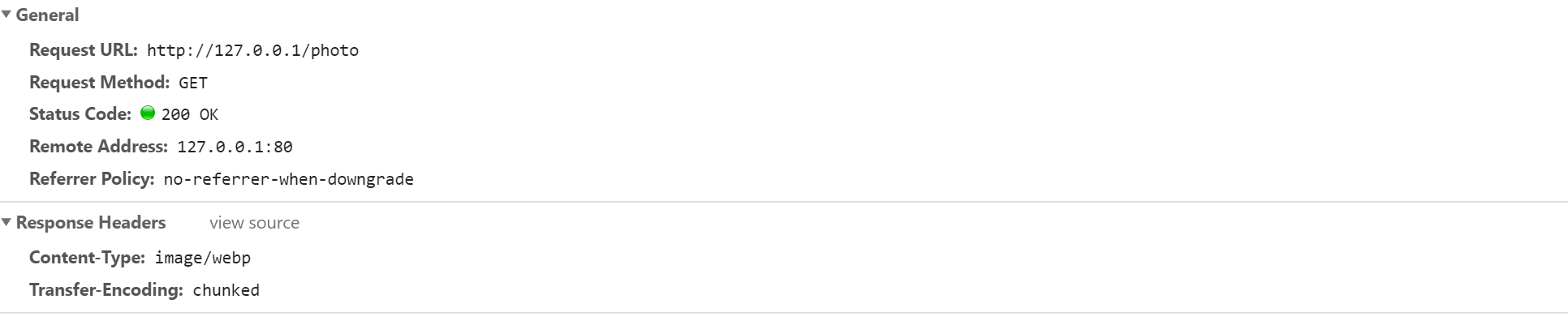
对test.html使用Content-Length,对test.webp使用chunk编码,且能够自动嗅探传输文件的格式。
本文完成了response的设置,实现的逻辑比较绕,代码的更改也比较分散,同时存在多个Writer反复封装的情况,不仅是不方便读者理解,也给这篇文章的书写带来了很大的麻烦,建议读者仔细品味并结合代码来完成阅读。
目前我们的框架还未提供路由功能,需要自己手动在handler中完成(*Request).URL.PATH到处理函数的映射,极为不方便。下一文则是给我们的框架提供简单的静态路由功能,最为硬核的功能已经完成,接下来都是些比较简单轻松的工作。
系列目录

